Is there an JumpCloud outage?
JumpCloud status: Systems Active
Last checked: 23 seconds ago
Get notified about any outages, downtime or incidents for JumpCloud and 1800+ other cloud vendors. Monitor 10 companies, for free.
Last checked: 23 seconds ago
Get notified about any outages, downtime or incidents for JumpCloud and 1800+ other cloud vendors. Monitor 10 companies, for free.
Outage and incident data over the last 30 days for JumpCloud.
Join OutLogger to be notified when any of your vendors or the components you use experience an outage. It's completely free and takes less than 2 minutes!
Sign Up NowOutlogger tracks the status of these components for Xero:
| Component | Status |
|---|---|
| Active Directory Integration | Active |
| Admin Console | Active |
| Agent | Active |
| Android EMM | Active |
| Commands | Active |
| Directory Insights | Active |
| Federation | Active |
| General Access API | Active |
| G Suite Integration | Active |
| JumpCloud GO | Active |
| JumpCloud University | Active |
| LDAP | Active |
| MDM | Active |
| Mobile Admin App: iOS and Android | Active |
| Multi-Tenant Portal (MTP) | Active |
| Office 365 Integration | Active |
| Password Manager | Active |
| Payment and Billing | Active |
| Policy Management | Active |
| RADIUS | Active |
| Remote Assist | Active |
| SCIM | Active |
| Self-Service Account Provisioning (Devices SSAP) | Active |
| Software Management | Active |
| SSO | Active |
| SSO | Maintenance |
| System Insights | Active |
| TOTP / MFA / JumpCloud Protect | Active |
| User Console | Active |
| User Import from CSV | Active |
| Workday Import | Active |
| www.jumpcloud.com | Active |
| Cloudflare | Active |
| Cloudflare CDN/Cache | Active |
| Cloudflare Cloudflare Firewall | Active |
| Security | Active |
| Security Advisories | Active |
| Security Notifications | Active |
| Support Services | Active |
| Email Support | Active |
| jumpcloud.com/support | Active |
| Premium Chat Support | Active |
| Premium Phone Support | Active |
View the latest incidents for JumpCloud and check for official updates:
Description: This incident has been resolved.
Status: Resolved
Impact: Minor | Started At: Feb. 22, 2024, 9:21 a.m.
Description: We have identified an issue upstream, outside of JumpCloud causing us to receive incomplete, malformed responses to our GET requests. We have contacted the Personio team and will work with them to resolve this as soon as possible. At this time we are resolving this as a JumpCloud issue.
Status: Resolved
Impact: Minor | Started At: Feb. 14, 2024, 12:40 a.m.
Description: This incident has been resolved.
Status: Resolved
Impact: Minor | Started At: Feb. 9, 2024, 1:12 p.m.
Description: This incident has been resolved.
Status: Resolved
Impact: Minor | Started At: Feb. 2, 2024, 5:04 p.m.
Description: # **JumpCloud Incident Report** **Date**: 2024-01-19 **Date of Incident**: 2024-01-15/16 **Description**: RCA for error rates on the JumpCloud Platform To start, we’d like to acknowledge and apologize for the impact these recent incidents have had. We pride ourselves in operating with excellence and work to limit the blast radius when things go wrong. We missed the mark here. **Summary:** There are three impact windows that will be discussed in this report. All times are MST. The first, on January 15th at 10:54 a subset of our systems began to have an elevated error rate. Failures manifested in new agent registrations failures, user bind failures, all device trust functionality including launching apps that had device trust enabled, and JumpCloud Go. Most local logins should have continued to function normally. At 10:57 our monitors paged one of our engineering teams and at 11:01 multiple other monitors triggered and more teams came online to support. At 11:24 a formal incident was declared internally and our incident management team came online to help coordinate all the teams in identifying and recovering the faulty systems. Because of the nature of the incident and because JumpCloud uses Device Trust the teams responding to the incident were unable to access certain systems so our break glass procedures were activated, this caused a significant delay in recovery efforts. As the teams began to gain access to the systems they were able to identify a single core service that was causing the errors. At 12:23 the team found failed authentications to the database and began work to access the needed systems to remediate the authentication failures. At 12:57 most services were recovered, and at 13:12 all systems reported as nominal. At this point the teams continued to work on finding the root cause of the ephemeral credential failure, but as we’d find out later we incorrectly assumed the issue was isolated to this single core service. The following day, on January 16th at 08:55, error rates began to rise on multiple systems including SSO, OIDC, user and admin logins, device authentications, and LDAP/RADIUS with MFA. At 08:58 automated alerts triggered to our teams and at 09:02 an internal incident was declared. Once the teams identified the issue and noticed it was the same as the previous day, remediation efforts quickly began at 09:08. By 09:15 all systems reported as nominal. Once these systems had been restored our teams immediately broke into multiple tracks to identify the root cause, work on evaluating and renewing all dynamic credentials, and to restore an old authentication mechanism to all services \(more on this in the root cause\). Renewal of all dynamic credentials was completed at 12:09. At 15:53 a release of our user portal had completed and at 15:54 errors began to rise on our login pages, active user sessions were still able to launch applications. The teams quickly started to rollback the release which completed at 16:05 but the error rate was still elevated. After further investigation they identified it being the same credential issue and fully restored service at 16:19. Once we recovered all systems from this incident we halted all production changes across the platform until we finalize our investigation. **Root Cause:** First let’s start with some context on how our services authenticate to our databases. Our services use dynamic credentials to authenticate to their respective databases, these credentials are ephemeral in nature and short lived. Each credential is tied to a token that is leased from a secrets backend and has a specific time-to-live \(TTL\). When a service needs access to a database credential it asks the system to grant it one, the system uses its token to ask the secrets backend for a new dynamic credential and passes that back to the service. Once that token’s TTL expires all child tokens and all credentials that were issued with that token are immediately revoked by the secrets backend. The token and credential lifecycles are fully automated. This diagram illustrates the tokens hierarchy and for the sake of clarity in this and the following diagram we’ll use daily round numbers for the TTLs. 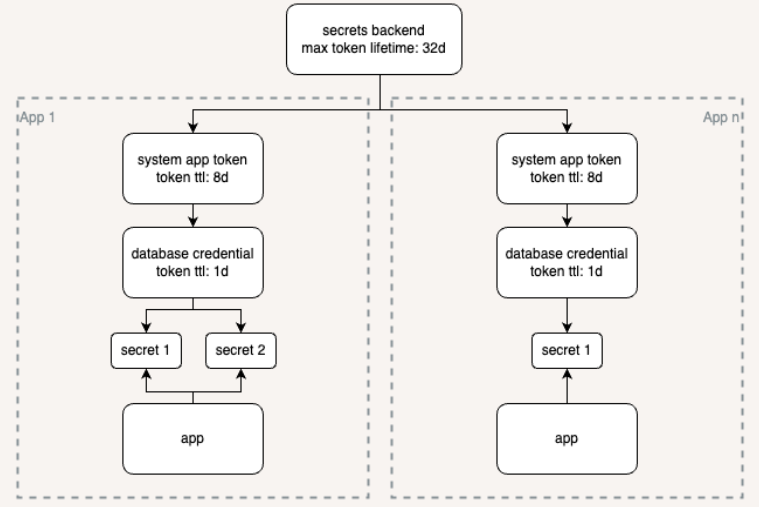 So what happened? In early December we began work on utilizing a new mechanism to request dynamic credentials. The services and secrets backend were untouched in this effort. Because the scope of the change was small the team working on this mechanism felt it was generally safe, this bypassed our usual path to production \(which is a more rigorous process involving architects and reliability engineers\). While these changes were reviewed, tested, and validated in staging environments certain caveats weren’t seen about its implementation until this incident. The origin of the issue stemmed from an attribute that was missing on the system token which defined its max lifetime. Because of this the token was leased with the secrets backend default max token lifetime. What made this issue particularly difficult to find was the fact that there are multiple attributes and layers where you can define the TTL. We did indeed set one of those attributes but mistook the way the hierarchy of TTLs interacted and functioned together with this new mechanism. Why didn't we catch this in our staging environment? That was due to the fact the secrets backend max token lifetime was 32 days. So all tokens and the credentials tied to them would be revoked after 32 days of the _first_ token being issued by that system token. This diagram illustrates that no matter how long the system token TTL was, because of the missing attribute the secrets backend enforces a 32 day maximum token lifetime and revokes all tokens and credentials at the end of its lifetime \(in red\). 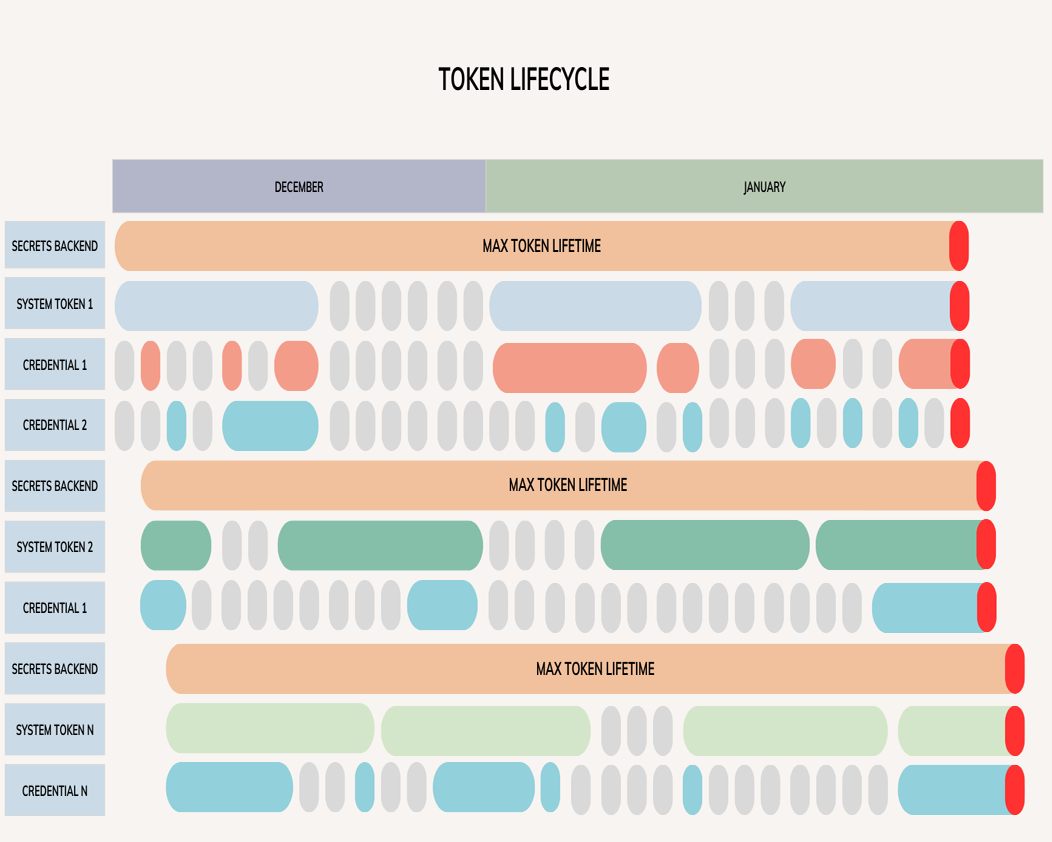 **Corrective Actions / Risk Mitigation:** 1. All credential and token renewals completed and verified - DONE 2. Revert of the secrets lifecycle management process - DONE 3. Additional monitoring and alerting around credential lifecycle - IN PROGRESS 4. Enhanced testing requirements for credential management changes - IN PROGRESS
Status: Postmortem
Impact: Major | Started At: Jan. 16, 2024, 11:15 p.m.
Join OutLogger to be notified when any of your vendors or the components you use experience an outage or down time. Join for free - no credit card required.